
Introduction
Web scraping means data extraction from a web page. It can be manual or by some other means. We will do it by python script with BeautifulSoup library. Purpose of web scraping is diverse. Web scraping technique can be used to extract people’s contact information. Some times it is used to scrap product price and information from popular online shopping webpage. The implementation of web scraping technique is huge. Our today’s example of web scraping python tutorial has no commercial purpose.
Importing python library
Some times we spend lots of time to choose a good movie to watch based on viewer’s ratings. My script will do this in minutes. The scripts will search on a pre specified web site on 5 pages (whatever you want). Each page contains at least 40 movies. So, the script will extract the movie name, release year, rating of around 200 movie. After that we will sort it based on the movie rating.
import requests from bs4 import BeautifulSoup as soup import pandas as pd import time import numpy as np
Python’s requests library allows us to send http request without manual labour. After that we parse the webpage by BeautifulSoup library. We will track the scraping time by the time library. We will need numpy library for array handling and pandas for data handling.
Starting with single page web scraping
my_url = 'https://123movies4u.cz/genre/science-fiction/page/2/' uClient = requests.get(my_url) page_soup = soup(uClient.text, 'html.parser') uClient.close()
We will scrap this https://123movies4u.cz/ web site. We will click on the movies for movies section. On genre we will click on Science Fiction. Now, on the bottom we will click on the page 2. You can click on any other page and any genre as you want. Now, we will copy the page URL and save it in “my_url” variable. At first we well set our script for one page. If it works for one page, then we will loop the script for 10 or 20 page or any other amount as we want. We will use requests library to send http request and get the webpage. After that the webpage will be parsed using BeautifulSoup library. Then, the http request will be closed. We will visit each movie webpage separately for scraping each movie information.
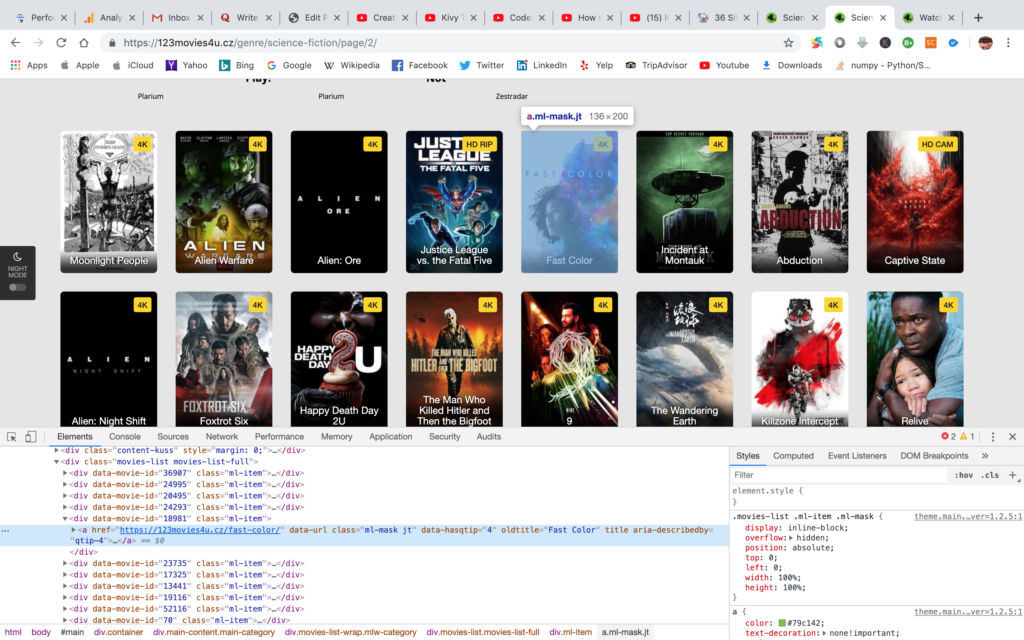
If we right click on a movie element and click on inspect. We will see something like the image above. All the movie item on this page are on ‘div’ tag, under the ‘class’ object of ‘ml-item’. So, we can pick all the 40 movie element in this page by “findAll” function and this is saved under mov_list. Now, we have all the 40 movie element, which have individual movie webpage URL inside. Now let’s pick number 5th movie element starting with zero. So, the 5th element’s index is 4. We can call that element by “mov_list[4]”. The individual movie webpage link is save under “a” tag. Everything inside a tag is dictionary element. Thus, individual movie links becomes “mov_list[4].a[‘href’]”. This is saved under “m_url” variable. Now we will send a http request to go inside a movie webpage. The whole code snippets is given below.
mov_list = page_soup.findAll('div',{'class':'ml-item'})
m_url = mov_list[4].a['href']
mClient = requests.get(m_url)
m_soup = soup(mClient.text, 'html.parser')
mClient.close()
Going inside a movie webpage and scraping
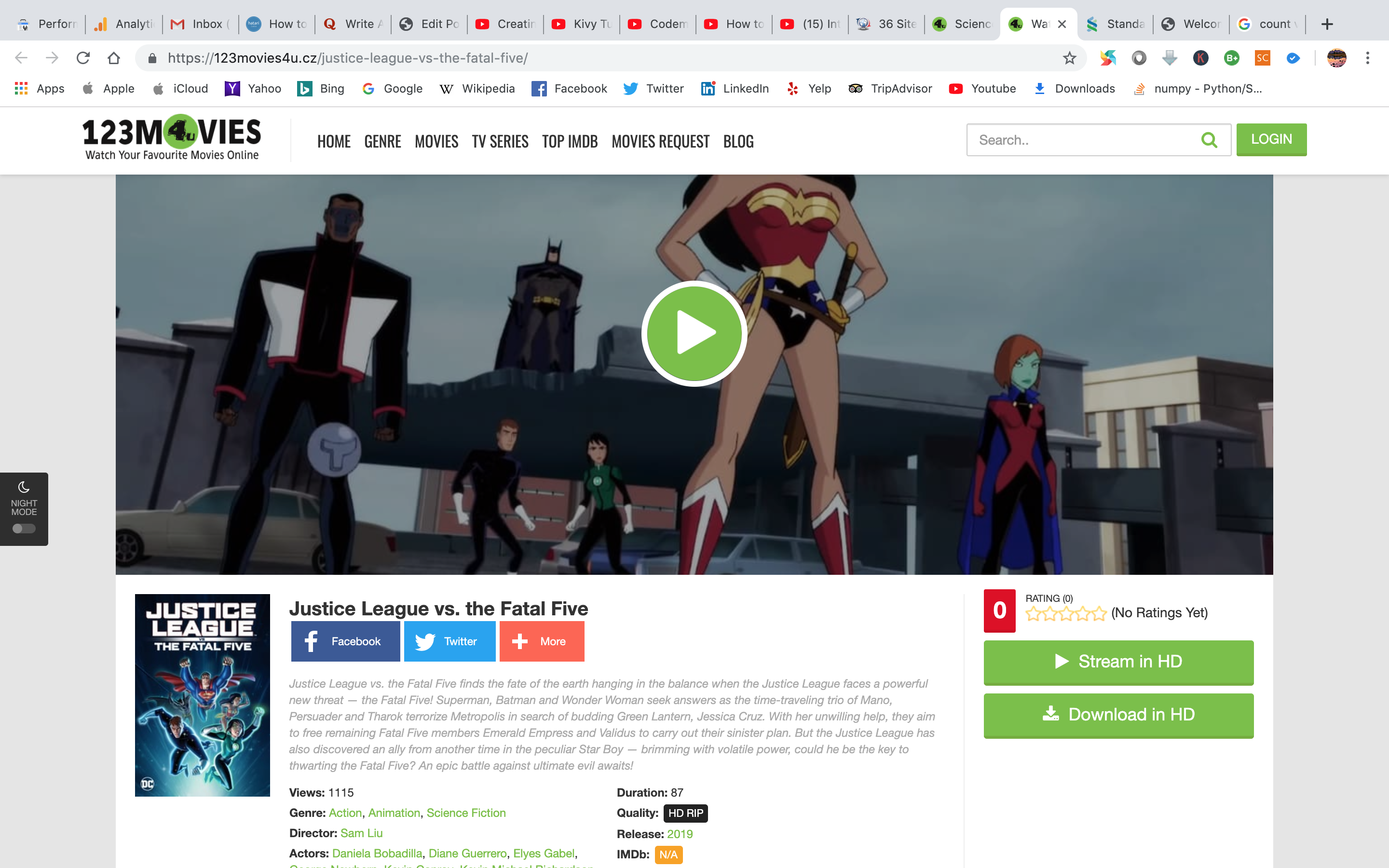
The content of individual movie webpage is saved under a variable named “m_soup” and the webpage looks like the image of individual movie webpage. From this webpage we will scrap movie name, movie release year and IMDb rating.
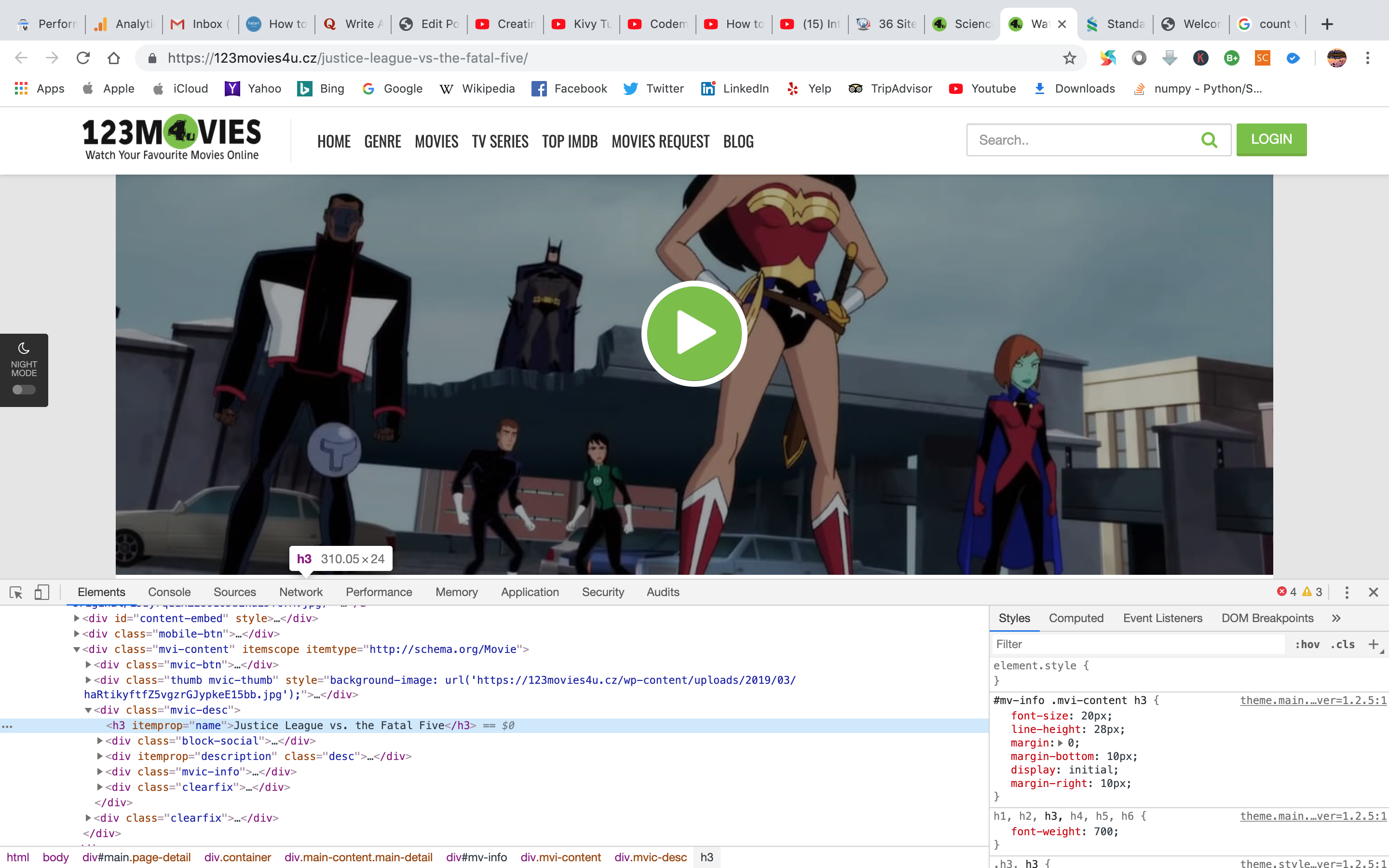
At first we will save the movie name. After right click on the big movie name and clicking on the inspect option we see that the movie name is under “h3” tag. So, from “h3” tag, it is very simple to extract text. the movie name is saved under “movie_name” variable.

Now, we will scrap the release year. After going into the inspect option of “release” text, we see that, release year is under “a” tag. But “a” tag is not unique. There are a lot of “a” tag through out the webpage. So, we have to go two step up of that “a” tag to find a unique tag and class. If we go two step up, we find a “div” tag with “class” object “mvici-right”. We will pick that object first. After that, we will pick “a” tag and from that we will pick the release year.
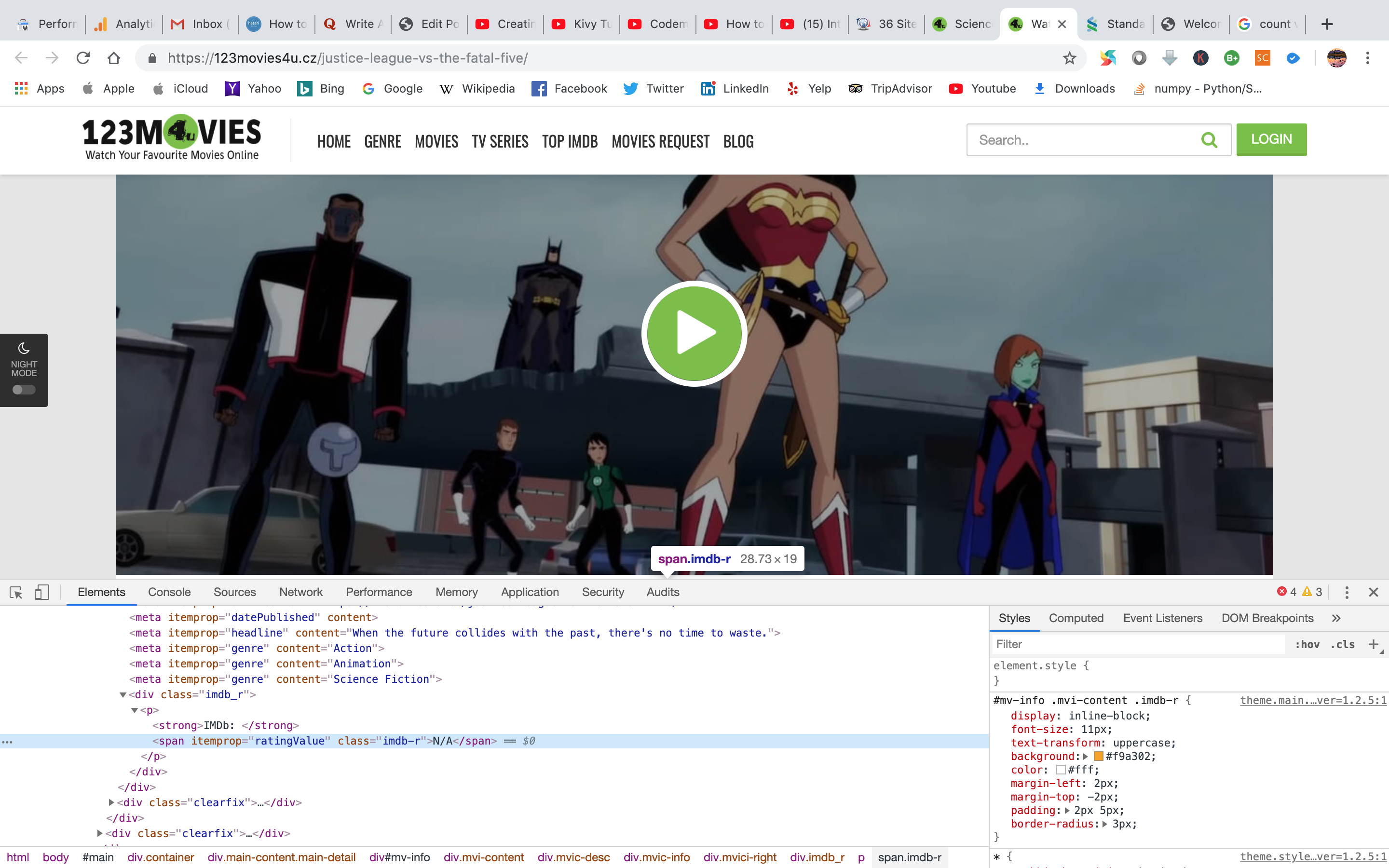
Now, we will scrap the movie rating. After inspecting the rating text element on the page, we see that it is under “span” tag “class” object is “imdb-r”. After scraping the rating, it is saved under the variable “rating”. The code snippet is given below.
movie_name = m_soup.h3.get_text()
all_a = m_soup.findAll('div', {'class':'mvici-right'})
release_year = all_a[0].findAll('a', {'rel':'tag'})[0].get_text()
rating = m_soup.findAll('span', {'class':'imdb-r'})[0].get_text()
Web scraping the whole thing
Our code now capable of scraping one movie information. Now, it is time to put everyting thing together and scrap as much as we want. We will use two for loop. One loop will scrap over every movie on a single page. Other loop will go through the amount of page we will define. For this case I have scrapped 5 pages. Some movies don’t have release year and rating. In those case the code will crush. For that case I have put two if else condition. One for release year and one for the rating. The whole code is given below.
movie_data = pd.DataFrame(columns=['Name','Year','Rating'])
pages = 5
for j in range(pages):
my_url = 'https://123movies4u.cz/genre/science-fiction/page/{}/'.format(j+1)
uClient = requests.get(my_url)
page_soup = soup(uClient.text, 'html.parser')
uClient.close()
mov_list = page_soup.findAll('div',{'class':'ml-item'})
for i in range(len(mov_list)):
m_url = mov_list[i].a['href']
mClient = requests.get(m_url)
m_soup = soup(mClient.text, 'html.parser')
mClient.close()
movie_name = m_soup.h3.get_text()
all_a = m_soup.findAll('div', {'class':'mvici-right'})#release_inf
a1 = all_a[0].findAll('a', {'rel':'tag'})#release year info
if len(a1)==0:
release_year = 'N/A'
else:
release_year = a1[0].get_text()
r1 = m_soup.findAll('span', {'class':'imdb-r'}) #rating info
if len(r1)==0:
rating = 'N/A'
else:
rating = r1[0].get_text()
movie_data.loc[(j*len(mov_list))+i]=[movie_name, release_year, rating]
print(i+1,movie_name, release_year, rating)
After scraping 200 movie we can see the top 10 movie list based on the rating.
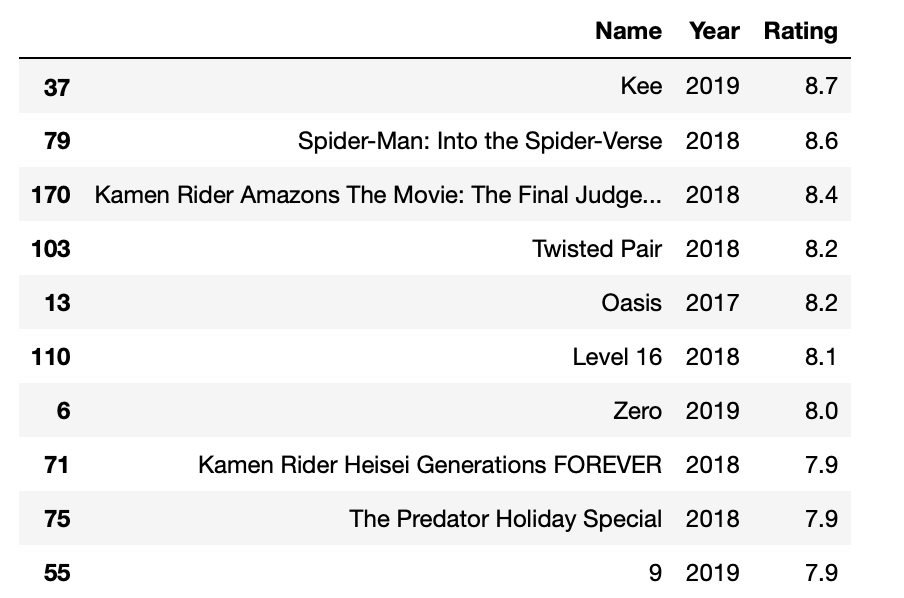
Concluding remarks
Manually going through 200 movies and collecting 3 attributes of each movie may take days. Perhaps, implementing web scraping technique saves time. Furthermore, commercial demand of this technique is huge. This post is only for fun and intro tutorial for web scraping by python. In future I will come up with new web scraping python tutorial. The Github repository link for the project is given below.
https://github.com/hasanbdimran/Web-Scraping
You can also check my fiver gig for web scraping.
https://www.fiverr.com/hasanbdimran/web-scrape-or-mine-data-from-a-webpage-or-website
hi there Mohammad – this is great – many many thanks for this gtreat howto and example. I love this.
many thanks for sharing. regards martin